安装xxl-job客户端一般有很多方式,我这里给大家提供两种安装方式,包含里面的各项配置等等。
前期需要准备好MySQL数据库。复制SQL到数据库里面。
#
# XXL-JOB v2.4.2-SNAPSHOT
# Copyright (c) 2015-present, xuxueli.
CREATE database if NOT EXISTS `xxl_job` default character set utf8mb4 collate utf8mb4_unicode_ci;
use `xxl_job`;
SET NAMES utf8mb4;
CREATE TABLE `xxl_job_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_desc` varchar(255) NOT NULL,
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`author` varchar(64) DEFAULT NULL COMMENT '作者',
`alarm_email` varchar(255) DEFAULT NULL COMMENT '报警邮件',
`schedule_type` varchar(50) NOT NULL DEFAULT 'NONE' COMMENT '调度类型',
`schedule_conf` varchar(128) DEFAULT NULL COMMENT '调度配置,值含义取决于调度类型',
`misfire_strategy` varchar(50) NOT NULL DEFAULT 'DO_NOTHING' COMMENT '调度过期策略',
`executor_route_strategy` varchar(50) DEFAULT NULL COMMENT '执行器路由策略',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_block_strategy` varchar(50) DEFAULT NULL COMMENT '阻塞处理策略',
`executor_timeout` int(11) NOT NULL DEFAULT '0' COMMENT '任务执行超时时间,单位秒',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`glue_type` varchar(50) NOT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) DEFAULT NULL COMMENT 'GLUE备注',
`glue_updatetime` datetime DEFAULT NULL COMMENT 'GLUE更新时间',
`child_jobid` varchar(255) DEFAULT NULL COMMENT '子任务ID,多个逗号分隔',
`trigger_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '调度状态:0-停止,1-运行',
`trigger_last_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '上次调度时间',
`trigger_next_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '下次调度时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`executor_address` varchar(255) DEFAULT NULL COMMENT '执行器地址,本次执行的地址',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_sharding_param` varchar(20) DEFAULT NULL COMMENT '执行器任务分片参数,格式如 1/2',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`trigger_time` datetime DEFAULT NULL COMMENT '调度-时间',
`trigger_code` int(11) NOT NULL COMMENT '调度-结果',
`trigger_msg` text COMMENT '调度-日志',
`handle_time` datetime DEFAULT NULL COMMENT '执行-时间',
`handle_code` int(11) NOT NULL COMMENT '执行-状态',
`handle_msg` text COMMENT '执行-日志',
`alarm_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败',
PRIMARY KEY (`id`),
KEY `I_trigger_time` (`trigger_time`),
KEY `I_handle_code` (`handle_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log_report` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`trigger_day` datetime DEFAULT NULL COMMENT '调度-时间',
`running_count` int(11) NOT NULL DEFAULT '0' COMMENT '运行中-日志数量',
`suc_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行成功-日志数量',
`fail_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行失败-日志数量',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `i_trigger_day` (`trigger_day`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_logglue` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`glue_type` varchar(50) DEFAULT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) NOT NULL COMMENT 'GLUE备注',
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_registry` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`registry_group` varchar(50) NOT NULL,
`registry_key` varchar(255) NOT NULL,
`registry_value` varchar(255) NOT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `i_g_k_v` (`registry_group`,`registry_key`,`registry_value`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_group` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`app_name` varchar(64) NOT NULL COMMENT '执行器AppName',
`title` varchar(12) NOT NULL COMMENT '执行器名称',
`address_type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '执行器地址类型:0=自动注册、1=手动录入',
`address_list` text COMMENT '执行器地址列表,多地址逗号分隔',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '账号',
`password` varchar(50) NOT NULL COMMENT '密码',
`role` tinyint(4) NOT NULL COMMENT '角色:0-普通用户、1-管理员',
`permission` varchar(255) DEFAULT NULL COMMENT '权限:执行器ID列表,多个逗号分割',
PRIMARY KEY (`id`),
UNIQUE KEY `i_username` (`username`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_lock` (
`lock_name` varchar(50) NOT NULL COMMENT '锁名称',
PRIMARY KEY (`lock_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `xxl_job_group`(`id`, `app_name`, `title`, `address_type`, `address_list`, `update_time`) VALUES (1, 'xxl-job-executor-sample', '示例执行器', 0, NULL, '2018-11-03 22:21:31' );
INSERT INTO `xxl_job_info`(`id`, `job_group`, `job_desc`, `add_time`, `update_time`, `author`, `alarm_email`, `schedule_type`, `schedule_conf`, `misfire_strategy`, `executor_route_strategy`, `executor_handler`, `executor_param`, `executor_block_strategy`, `executor_timeout`, `executor_fail_retry_count`, `glue_type`, `glue_source`, `glue_remark`, `glue_updatetime`, `child_jobid`) VALUES (1, 1, '测试任务1', '2018-11-03 22:21:31', '2018-11-03 22:21:31', 'XXL', '', 'CRON', '0 0 0 * * ? *', 'DO_NOTHING', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化', '2018-11-03 22:21:31', '');
INSERT INTO `xxl_job_user`(`id`, `username`, `password`, `role`, `permission`) VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
INSERT INTO `xxl_job_lock` ( `lock_name`) VALUES ( 'schedule_lock');
commit;
docker服务器安装xxl-job集成xxl-job
拉取指定版本:
docker pull xuxueli/xxl-job-admin:2.4.0
在根目录创建data文件夹,然后创建xxl-job文件夹,启用docker镜像,注意修改里面MySQL的账号密码,以及 xxl.job.accessToken,这个我们随机定义一串长字符串,主要用于调度时交互使用
docker run -di -e PARAMS="--spring.datasource.url=jdbc:mysql://172.17.0.1:3306/xxl_job?Unicode=true&characterEncoding=UTF-8 --spring.datasource.username=root --spring.datasource.password=1111 --xxl.job.accessToken=aaaaaaaaaaaa.ddss.cccc" \
-p 9001:8080 \
-v /data/xxl-job:/data/applogs \
--name xxl-job \
--privileged=true \
xuxueli/xxl-job-admin:2.4.0完成以后我们开放服务器端口9001,然后使用http://服务器ip:9001/xxl-job-admin 进行访问,输入账号admin 密码 123456 即可
集成SpringBoot: 我们在本地搭建一个SpringBoot项目,使用本地项目连接服务器xxl-job进行调度。
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.4.1</version>
</dependency>
xxl.job:
admin:
#这个是我们的服务器xxl-job后台访问地址
addresses: http://服务器ip:9001/xxl-job-admin
#这个就是服务器创建镜像时设置的 xxl.job.accessToken
accessToken: aaaaaaaaaaaa.ddss.cccc
executor:
#这个是xxl-job管理后台(执行器管理)里面的AppName 名称
appname: web-server
#不填就是使用默认的自动录入
address: ""
#不填就是使用默认的
ip: ""
#指定使用9990进行调度任务通信
port: 9990
logpath: ""
#日志只保存5天的
logretentiondays: 5在项目里面创建一个类,使用xxlJob注解
java">package com.app.web.task;
import com.xxl.job.core.handler.IJobHandler;
import com.xxl.job.core.handler.annotation.XxlJob;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
@Component
@Slf4j
public class MyJobHandler{
@XxlJob("demoJobHandler")
public void execute(){
log.info("任务调用成功啦,哈哈哈哈哈哈哈哈哈哈哈哈哈");
}
}
由于我们是本地服务器连接测试服务器上面的xxl-job,所以这里的注入方式我们需要改成一个服务器能访问到我们本地端口9990的服务,我们将注册方式改为手动录入,并填入能访问我们本地服务的链接
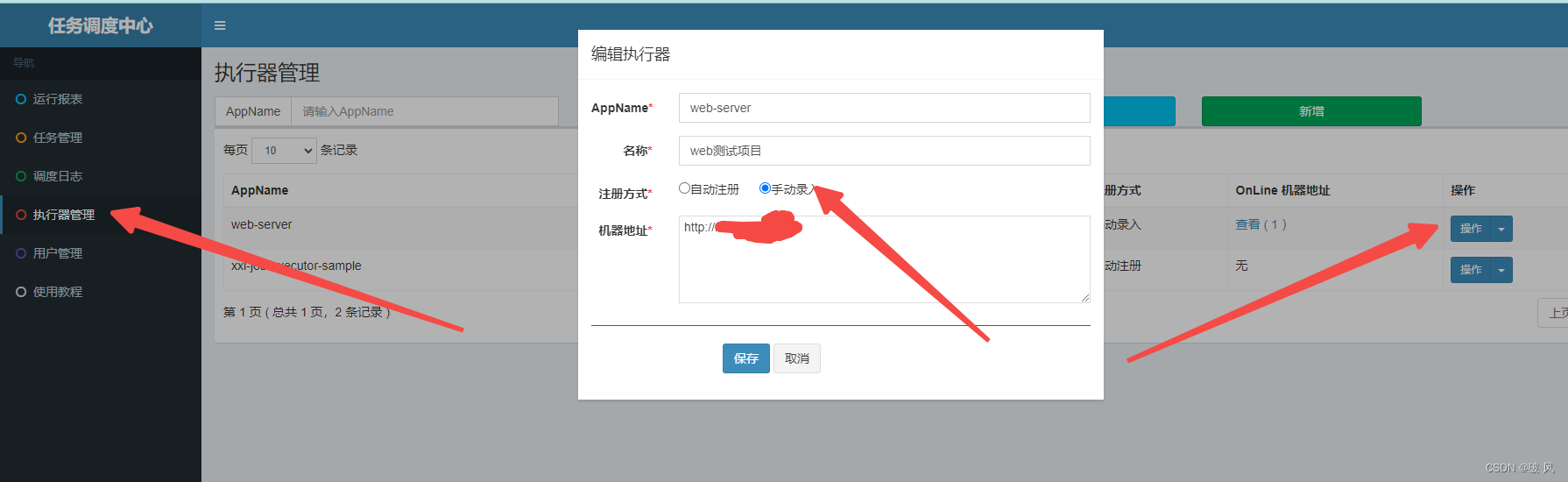
点击任务管理,添加如下:
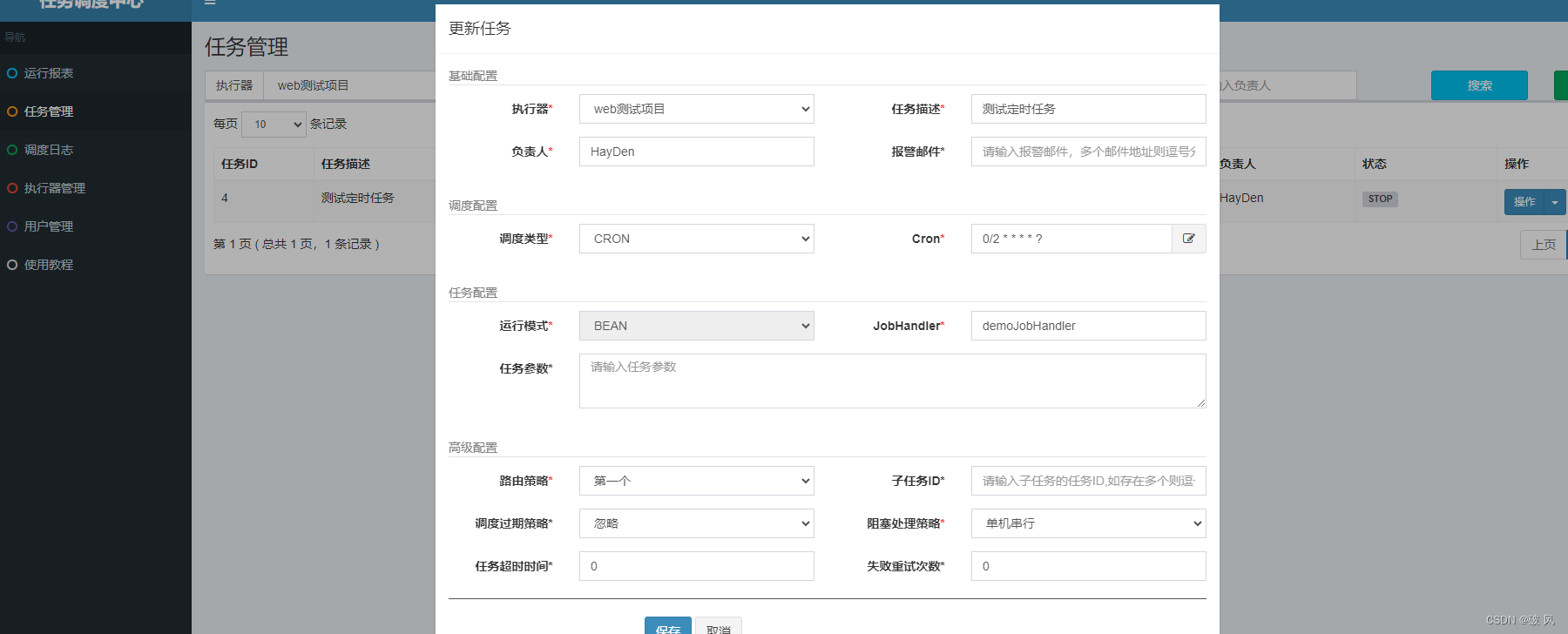
然后本地项目启动,点击执行任务,任务调度成功。。。。。。。。。。。

搭建xxl-job系统
本地搭建xxl-job项目本地服务启动,下载项目源码:https://github.com/xuxueli/xxl-job/,下载完成以后主要也是修改admin模块下面配置文件application.properties。修改里面数据库连接方式以及xxl.job.accessToken,打包项目然后启动服务即可。启动成功以后访问 http://127.0.0.1:9001/xxl-job-admin,注意端口一定要和本地xxl-job项目端口一致。
xxl.job:
admin:
#这个是我们的服务器xxl-job后台访问地址
addresses: http://服务器ip:9001/xxl-job-admin
#这个就是服务器创建镜像时设置的 xxl.job.accessToken
accessToken: aaaaaaaaaaaa.ddss.cccc
executor:
#这个是xxl-job管理后台(执行器管理)里面的AppName 名称
appname: web-server
#不填就是使用默认的自动录入
address: ""
#不填就是使用默认的
ip: ""
#小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口
port: 0
logpath: ""
#日志只保存5天的
logretentiondays: 5
最后各个参数详细解释如下,不明白的可以在看一下具体的
-
admin: addresses
- 含义: 这是 XxlJob Admin 的地址,用于 XxlJob Executor 连接到 XxlJob Admin 进行注册和任务调度通信。
- 示例:
http://服务器ip:9001/xxl-job-admin - 作用: Executor 通过这个地址向 XxlJob Admin 注册,并从 Admin 处接收任务调度信息。
-
accessToken
- 含义: 这是用于 Executor 与 Admin 之间通信的令牌,用来进行身份验证。
- 示例:
aaaaaaaaaaaa.ddss.cccc - 作用: 确保通信安全,只有持有正确令牌的 Executor 才能注册和与 Admin 通信。
-
executor: appname
- 含义: 执行器的应用名称,通常在 XxlJob Admin 中用于区分不同的执行器实例。
- 示例:
web-server - 作用: 在 XxlJob Admin 中识别和管理该 Executor 实例。
-
executor: address
- 含义: 手动指定 Executor 的地址。通常情况下可以留空,由系统自动获取。
- 示例:
"" - 作用: 允许手动指定 Executor 的地址,便于在某些特定网络环境下进行特殊配置。
-
executor: ip
- 含义: 手动指定 Executor 的 IP 地址。通常情况下可以留空,由系统自动获取。
- 示例:
"" - 作用: 允许手动指定 Executor 的 IP 地址,便于在某些特定网络环境下进行特殊配置。
-
executor: port
- 含义: Executor 监听的端口号。如果设置为 0 或不设置,则会自动选择一个端口(默认是 9999)。
- 示例:
0 - 作用: 在同一台机器上运行多个 Executor 实例时,需要设置不同的端口号避免冲突。
-
executor: logpath
- 含义: 执行器日志的存放路径。
- 示例:
"" - 作用: 指定 Executor 生成的日志文件存放的目录。如果不设置,系统会使用默认路径。
-
executor: logretentiondays
- 含义: 日志保留的天数。
- 示例:
5 - 作用: 指定日志文件保留的天数,超过这个天数的日志文件会被自动清理,避免日志文件占用过多磁盘空间。