GUICourse: From General Vision Language Model to Versatile GUI Agent
- 前言
- Abstract
- Motivation
- Solution
- GUICourse
- GUIEnv
- GUIEnv-global
- GUIEnv-local
- GUIAct
- GUIAct (web-single)
- GUIAct (web-multi)
- GUIAct (smartphone)
- GUIChat
- Experiments
- Main Result
- Ablation Study
- Conclusion
前言
一篇关于构建提升GUI智能体能力的数据集的文章,文章提到的关于提升GUI能力的三个点听起来还是比较合理的,此外,数据集的数量非常丰富,比起一些benchmark只提供几百条数据显得很有诚意。总的来说是关于提升GUI智能体能力的一个比较有想法的工作。
| Paper | https://arxiv.org/pdf/2406.11317 |
|---|---|
| Github | https://github.com/yiye3/GUICourse |
Abstract
VLMs的进步得以帮助人类完成GUI任务,然而,现有的VLMs受到基础能力(OCR & grounding)以及GUI知识方面的挑战,这阻碍了它们成为实用的GUI智能体。为此,本文提出GUICourse,用于训练基于VLMs的GUI智能体的数据集。首先,作者提出GUIEnv数据集来增强VLMs的OCR和grounding能力。接着,作者提出GUIAct和GUIChat数据集用于增强GUI组件和交互的知识。实验证明基于本数据集的GUI智能体在通用的GUI任务上有更好的表现。最后作者通过消融实验分析了不同的变体。
Motivation
现有关于GUI智能体的工作可以分为基于文本和基于视觉的。基于视觉的智能体有两点优势:
- 容易获取(直接截图)。
- 具有可迁移性(GUI视觉元素相似)。
然而基于视觉的智能体严重依赖VLMs的基础能力和内部知识,但是当前VLMs有如下问题:
- grounding能力不足以定位GUI元素。
- 对GUI图标的理解不够。
Solution

因此,为了提高当前VLMs的基础能力和GUI知识,本文提出GUICourse,包含了三个数据集:
- GUIEnv: 10M website page annotation pairs作为预训练数据,0.7M region-text QA pairs作为SFT数据。目的是增强VLMs的grounding能力。
- GUIAct: 67K单步和15K多步动作指令,增强VLMs的GUI知识。
- GUIChat: 44Ksingle-turn QA pairs和6k multi-turn dialogues with text-rich images and bounding boxes,提升GUI智能体的交互能力。
基于上述数据,作者对一些VLMs进行训练,在多个数据集上都取得了明显提升。消融实验也证明GUIEnv数据集对提升VLMs的grounding能力是有帮助的。
GUICourse
GUIEnv

OCR和grounding是GUI 智能体的基础能力,本数据集是为了增强VLMs的这两方面能力。
GUIEnv-global
- 描述:每个样本是一个长文本,包含一张页面上所有可描述的内容。
- 收集方式:从C4收集4M URLs,部署Playwright得到10M标注后的网页截图。
GUIEnv-local
- 描述:每个样本是一个region的QA对,text2bbox或者bbox2text。
- 收集方式:
- 裁剪成小于1920×1080的分区。
- 删除元素少于10个的截图。
- 随机选取10个带有文本和位置的元素作为text2bbox和bbox2text的任务数据。
GUIAct
GUI元素的功能和控制方法对于GUI智能体来说非常重要,为此需要一个数据集来增强VLMs的GUI知识。GUIAct涉及网页和手机两个场景,分为三个不同partition:web-single,web-multi 以及 smartphone。
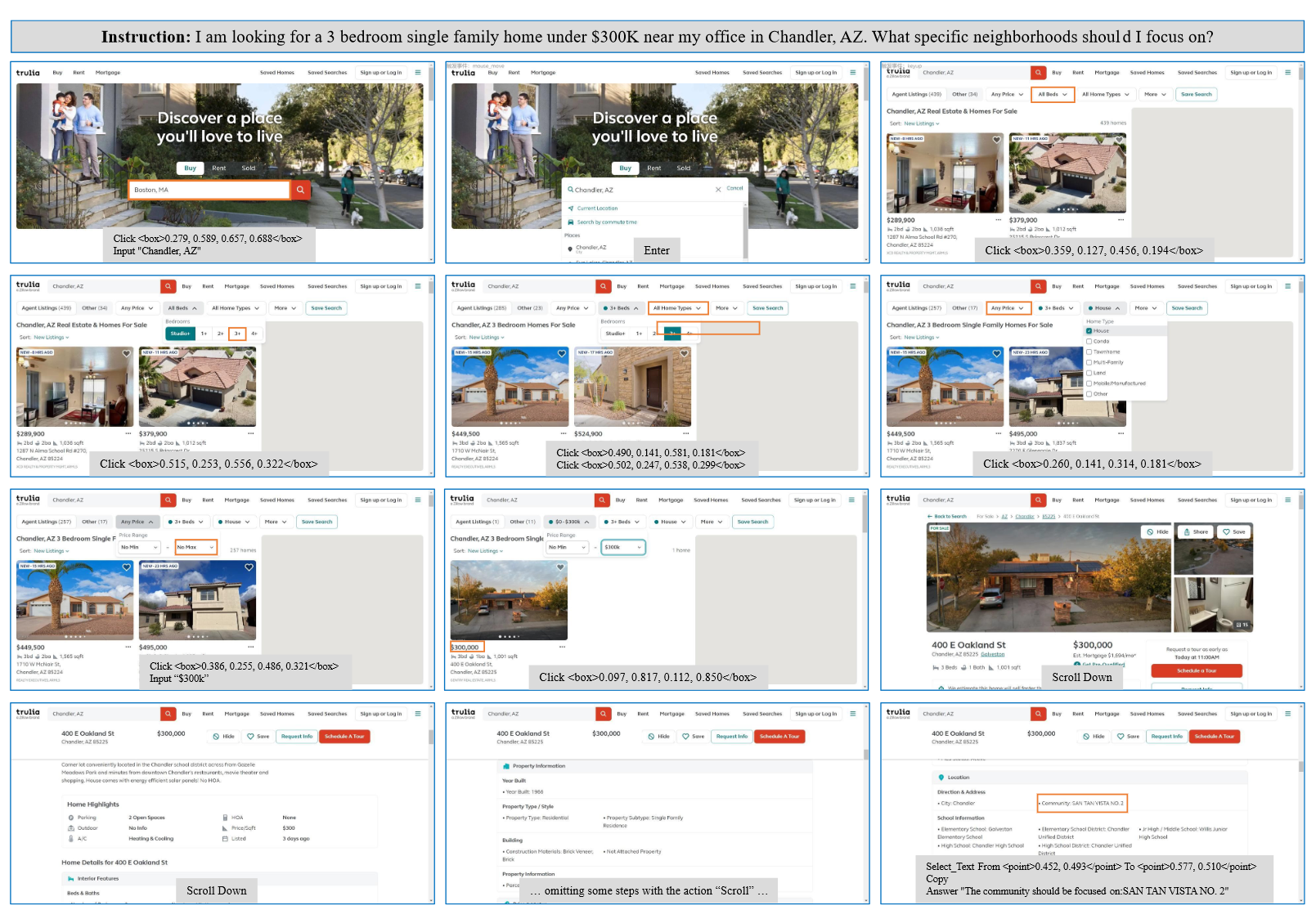
GUIAct (web-single)
- 描述:每个样本由一个任务的自然语言描述,页面截图以及对应操作元素的bbox。
- 收集方式:
- GPT-4汇总不同场景的网址,利用超链接进行扩展,获得50个域名和13k个网站。
- 使用网页快照工具获取HTML、交互元素以及截图。
- 使用GPT-4V获取每个网页的单步指令动作对,得到70K个数据。
- 人工检查GPT-4V的标注结果,将准确率从55%提升到92%。最后得到76K数据。
GUIAct (web-multi)
- 描述:每个高级指令对应多跳操作,每一跳操作对应一个网页截图和对应的操作指令。
- 收集方式:
- 收集八个场景的121个网页。
- 使用GPT-3.5和Claude2为每个网页生成指令,得到8K条high-level指令,每条指令都需要与网页进行多步交互。
- 开发了一个在线标注插件工具,雇佣标注人员执行操作完成相应指令。最终得到5696条多跳指令,相当于44K个训练样本。
GUIAct (smartphone)
- 描述:样本样例如下:

- 收集方式:AITW的子集,选取“General”标签数据并筛选掉没有底部导航栏的截图,得到9157个多步操作,对应67K个训练样本。
GUIChat
自然语言交互对更好使用智能体很重要,因此在智能体训练阶段有必要融合对话数据。GUIChat数据集包含大量富文本的网页截图,包括44K个单轮QA对和6K个多轮对话。
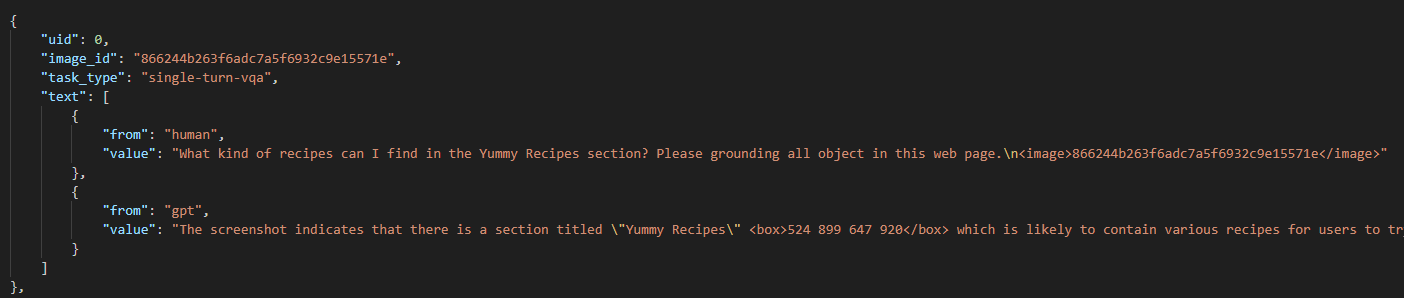
- 描述:每个样本包括截图,人类对话,以及GPT生成的关于截图上对应对话内容的描述。如果是多轮对话,就是一张截图,然后多轮的人类对话和GPT生成的截图上对应对话的内容。
- 收集方式:
- 使用Playerwright得到网址截图。
- 从DOM tree中抽取必要的结构化和文本信息。
- 利用GPT-4根据抽取的文本信息构建问答对。
Experiments
Main Result
对多个GUI智能体在GUICourse上进行训练,在常规GUI任务包括Mind2Web,AITW上进行评估。结果如下:
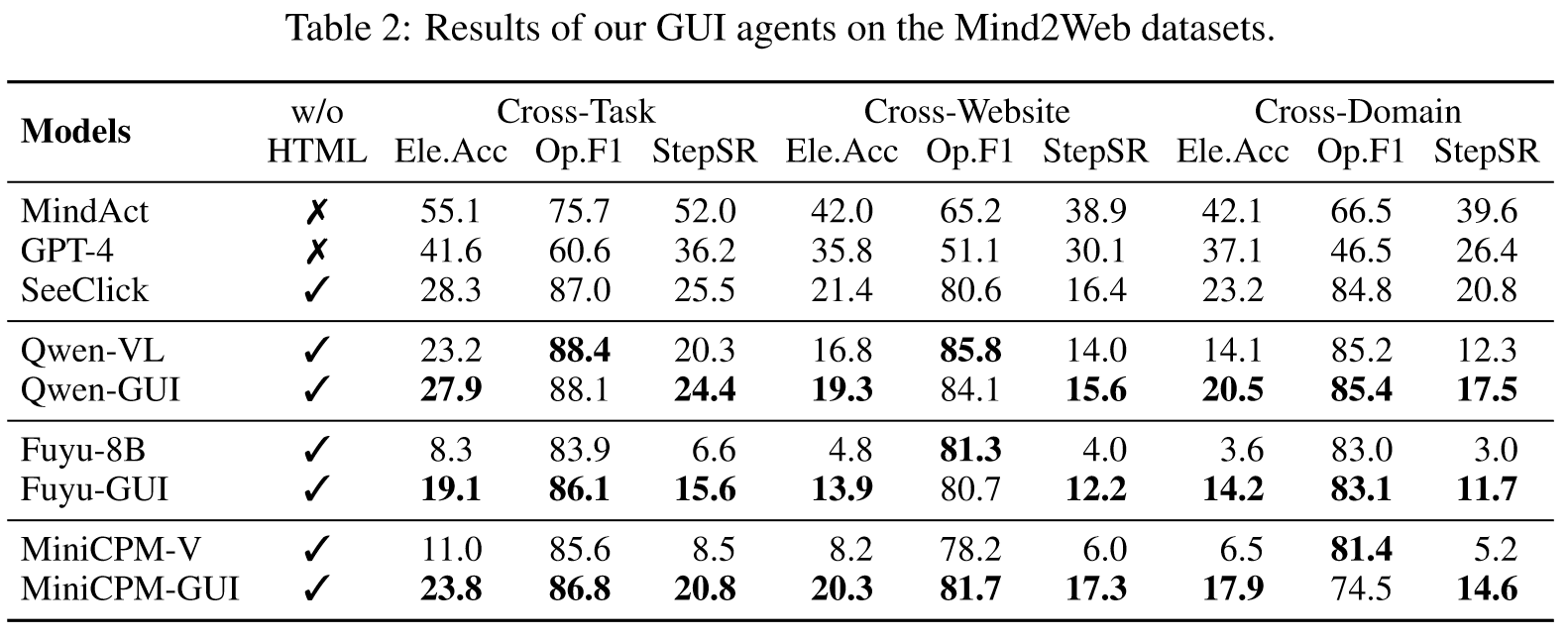
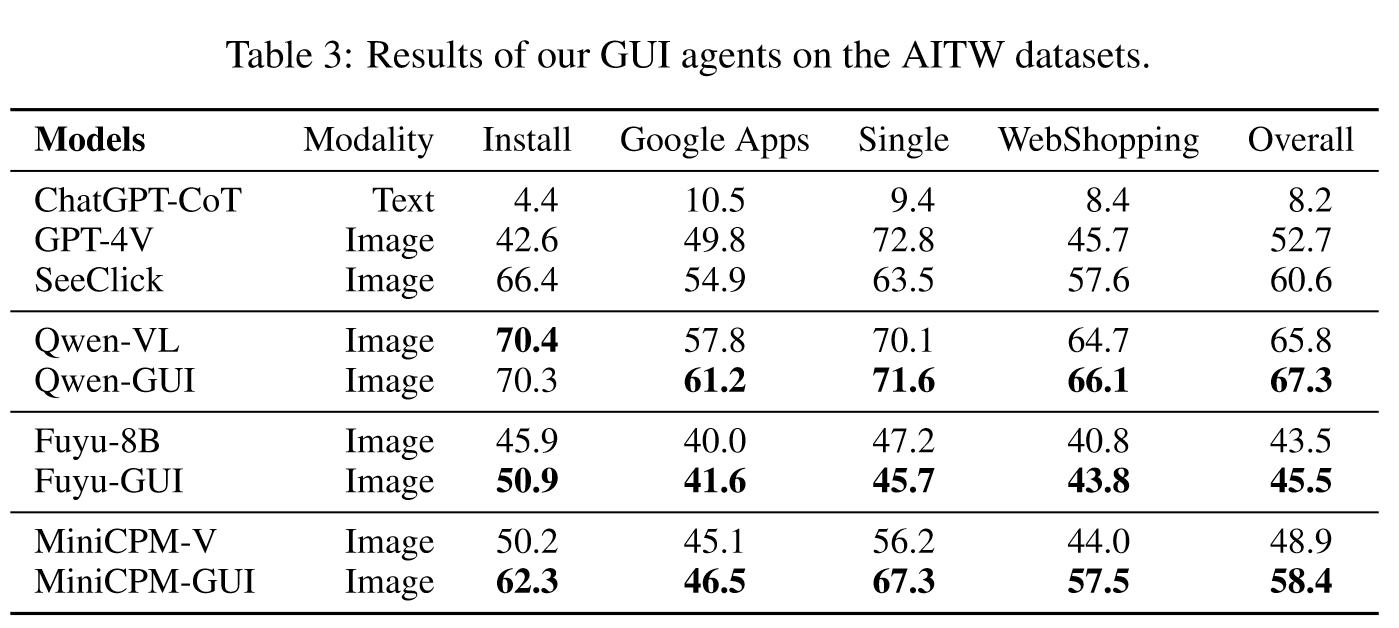
结果表明,GUICourse可以帮助GUI智能体得到比baseline更好的性能。
Ablation Study
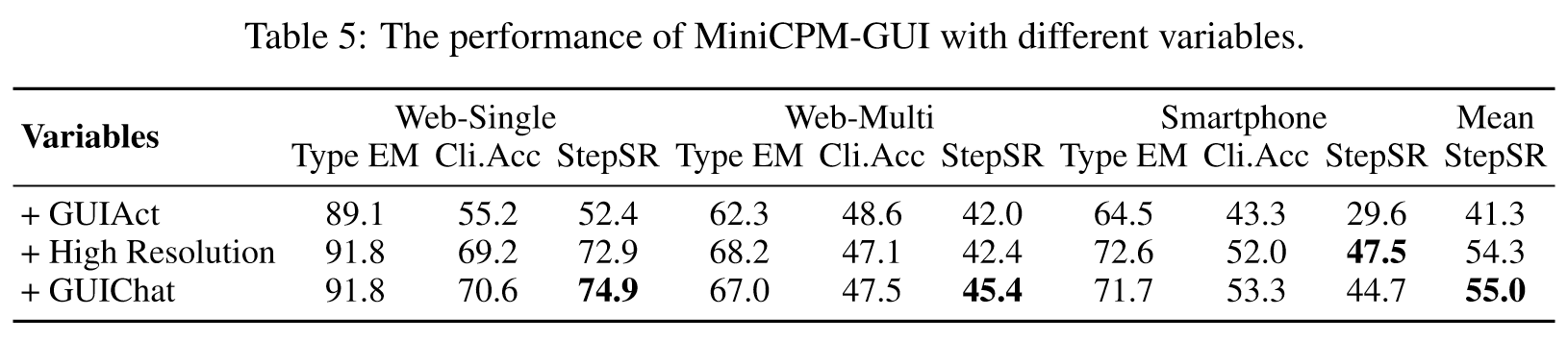
本小节涉及两个消融实验,第一个消融实验通过调节GUIEnv-global数据的数量,来分析MiniCPM-GUI的性能。第二个实验以通用的VLM MiniCPM-V为基线,依次添加GUIAct、提高分辨率、混合GUIChat数据集。结果如下表所示:
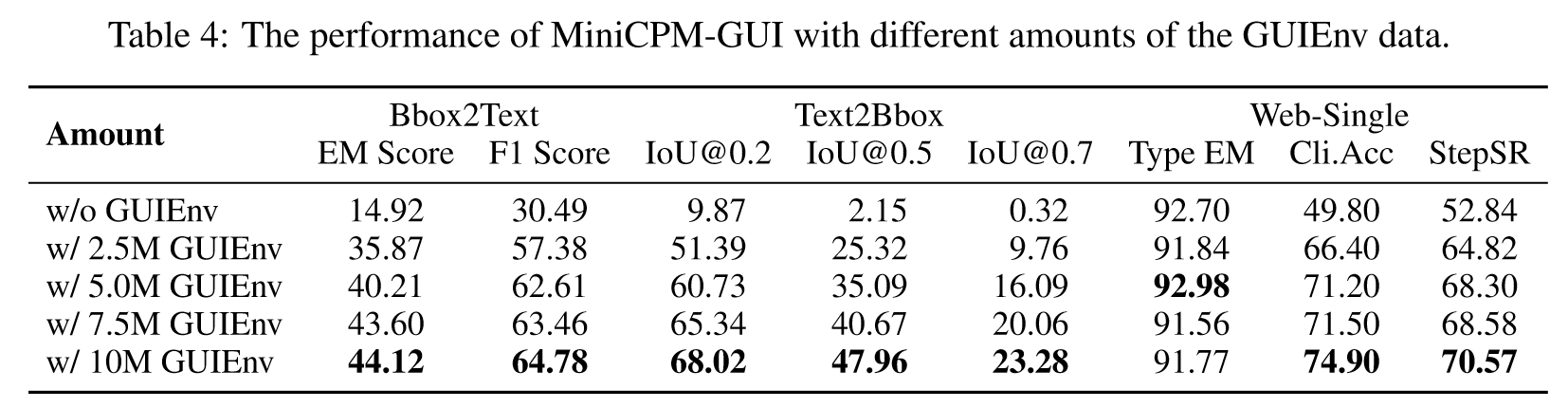
- GUIEnv数据集对提高VLM的基本能力和GUI导航能力很有用。其中从没有GUIEnv,到使用2.5M GUIEnv数据,性能提升是显著的,说明GUI grounding是必要的。
- 高分辨率对GUI导航任务非常重要,在 web-single 和 smartphone 任务上有巨大提升,但是 web-manual 上没有提升,可能对于复杂指令和环境来说,只是提升分辨率是不够的。
- GUIChat数据集对于网页场景有效。
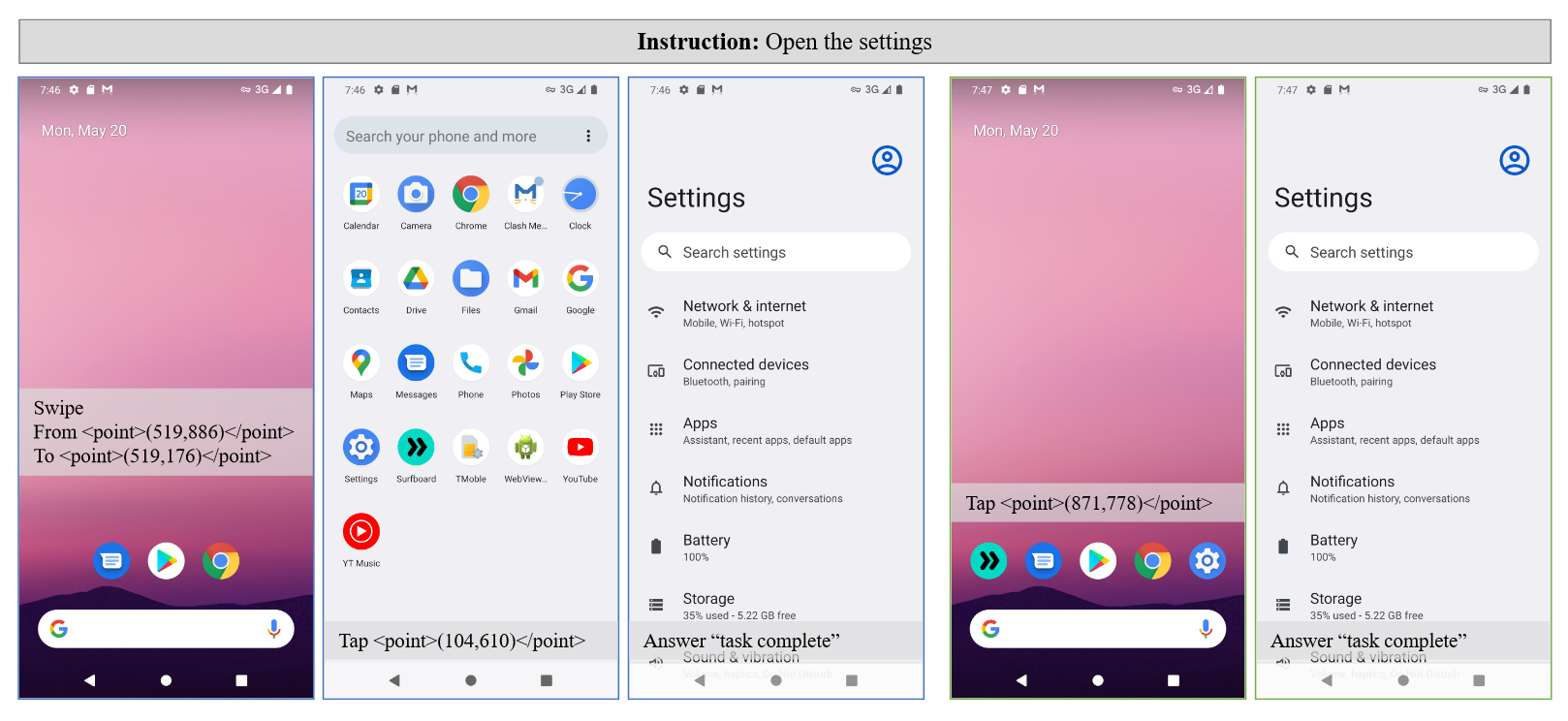
之后作者又做了一些case study如下:

Conclusion
本文构建了GUICourse数据集,帮助提升GUI智能体的grounding能力,GUI知识以及GUI的交互能力。实验结果表明了数据集的有效性,消融实验也证明了数据集有助于提高GUI导航能力。
这篇工作思路非常清晰,故事浅显易懂,直接点明当前GUI在grounding、GUI知识以及交互能力上的不足。但是这篇工作我读下来还是有一些问题:
- 虽然这些点看起来合理且显而易见,但是作者并没有实验去说明这些问题,也就是说,这几个问题的论据不足,只是读起来合理。
- 实验部分的提点不高,让我对数据集的可靠性产生了怀疑,GUIEnv数据集没什么问题,提高grounding能力在很多文章都证明是有效的,但是GUIAct和GUIChat数据集到底有没有作用文中并没能够证明,估计是缺少相应的数据集来验证吧。
- 大量的QA任务作为预训练数据,可能并不是特别适合GUI智能体学习新知识,个人拙见。
- 文章中错字,数据错误较多,可能因为工作比较赶吧。